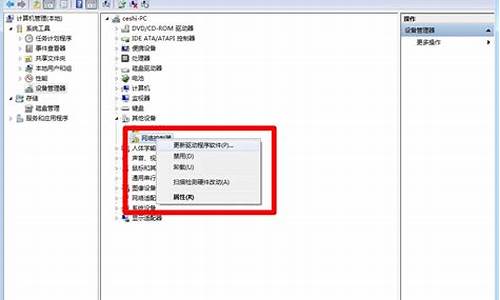
1.为什么我最近重装系统后某些应用程序中的汉字就变成了乱码?
2.文件的“编码”是指什么?
3.小弟玩三国志7中文版+威力加强版 求内码转换工具!要下载地址!谢!
4.幻想水浒传2内码问题
5.更改游戏内码问题
老牌劲旅——南极星
南极星是老牌的内码转换平台,还记得以前安装完游戏后的“USE NJWIN TO PLAY IT”么?这个NJStar就是南极星公司为了便于网络浏览而开发的增强版NJWin。它除了继承南极星的全部优点(中文编码优异)外又加入了输入法、文本文件内码转换,并针对网络进行了优化,名字也就改成了NJStar Communicator。看看界面,是不是华丽了很多?
点击Current Coding Button(当前使用的内码按钮),显示现在使用的内码,它包括以下选项:
A. Ansi/No CJK Support 使用当前系统的内码浏览,也就是说不具备转码能力
(1).Chinese Auto Simplified 自动识别两种中文(Big5和GB)内码并用简体显示
(2).Chinese Auto Traditional 自动识别两种中文内码并用繁体显示
(3).Chinese GB Simplified 将文字转换成GB码并用简体显示
(4).Chinese GB Traditional 将文字转换成GB码并用繁体显示
(5).Chinese Big5 Simplified 将文字转换成Big5码并用简体显示
(6).Chinese Big5 Traditional 将文字转换成Big5码并用繁体显示
(7).Chinese GBK Simplified 将文字转换成GBK码并用简体显示
(8).Chinese GBK Traditional 将文字转换成GBK码并用繁体显示
J.Japanese Auto Detect 自动识别日文
E.Japanese EUC-JIS 将文字转换成日文EUC-JIS码
S.Japanese Shift-JIS 将文字转换成日文Shift-JIS码
K.Korean KSC 5601 将文字转换成韩文码
由于日文内码也比较多,因此最好用自动选择。Big5(大五码)是台湾和香港普遍使用的汉字内码,大陆主要使用GB(国家标准码,只有常用的汉字)和GBK(国家标准扩展码,加入了繁体汉字和生僻汉字等)内码。
汉字通
比起澳大利亚的南极星,台湾同胞编写的汉字通可是有过之而无不及!
汉字码档案转码用来将不同内码的文本文件转换成本机使用的内码。唯一的缺陷是不支持长文件名,如果转换长文件名文件,在转换后要将文件名改回来。
左边区域是源文件,在Code中选择原文本文件的内码,点击File选择要转换的文件。
右边区域是目标文件,在Code里选择要转换成的文件,然后点击Convert即可。一般来说,如果源文件是Big5(大五码)的话,在目标文件中选择GB码时,生成的文件就是简体中文GB码。如果目标文件选择GBK码时,就会生成中文繁体。
黑马——MagicWin98
这款98年出品的多内码平台推出没多久就好评如潮,它编码准确,可以字库,以达到字型显示最优效果。其外观和南极星有些相似,主要选项也较接近南极星。
主菜单主要包含以下选项:
Options(设置),几乎所有的MagicWin98的设置都在这里。用分页分成了General(一般性选项)、Font(字体)、Text(文本)、Window System(系统类型)和Chinese Mode(中文模式)四项。
General区:从上到下分别是自动刷新屏幕(当更改设定后,MagicWin将会自动刷新屏幕以便设定生效)、总是在前、MagicWin启动时最小化、启动时出现在上次退出时的位置、在自动检测内码时使用EUC作为日文内码、使用智能检测模式、保存每次的设定、使用热键(Ctrl-AltKey呼出MagicWin)(图5)。
Text区:选定这个选项可以只转换当前浏览窗口(应用程序)而不破坏其它的窗口文字,这样就不会出现只有当前窗口文字显示正常而其它窗口全部是乱码的现象,建议选定。
Window System区:分别是非CJK(中日韩)Windows系统、简体中文Windows、繁体中文Windows、日文SJIS内码Windows、日文EUC内码Windows、韩文EUC内码Windows。按你当前使用的Windows系统选择。如果不是中日韩系统的话(如英文Windows),选择第一个。
我认为玩日本游戏首选汉字通,玩中文繁体游戏首选南极星;同样的道理,看日文网站用汉字通,中文网站用南极星,韩文网站用MagicWin98。如果你嫌麻烦的话,就挂上一个MagicWin98或者是Richwin吧!这是我个人从各个方面综合评估后得出的结论,仅供参考,你可根据自己的需要任选一种。内码平台的编码率是有限的,任何一种内码转换软件都不能100%地识别出所有内码,因此,当你遇到无法识别的内码时,试试同时使用两种内码平台进行转码,可能会得到意想不到的效果。
为什么我最近重装系统后某些应用程序中的汉字就变成了乱码?
那是繁体中文,显示成乱码。
-
乱码解决方案
我在2000年刚开始用win98时,繁体游戏是乱码的,装了office2000并用自定义安装把繁体字装进去就能正常显示繁体字。直接用金山快译,点菜单栏的“码”字,选big 5(繁体中文大五码)也可。winxp用多国语言版能正常显示繁体字。2000年后我从未碰到乱码,解决方案只能从网上搜。
-
从游侠补丁网找到这些:
化繁为简 V2.13版(最佳游戏简繁体转换软件)
://patch.ali213.net/view.asp?id=3110
这是微软根据winxp制作的繁简转换工具的修正版本。
1.将目录复制到硬盘。
2.执行W2kXpCJK.exe
3.在游戏文件栏里选取你所需转换的游戏的执行文件。(如C:\GAME\gulong.exe)然后运行化繁为简即可。
-
在百度知道搜到以下内容:
目前主要是台湾地区游戏和光荣系列游戏需要繁体或者乱码需要解决,可以按照常规方法或是不同系统进行分类解决
1、常规软件:内码转化工具MagicWin或者南极星
内码转化工具MagicWin下载地址:://down.52pk.net/soft/730.htm
主要解决方向是光荣系列游戏的乱码问题,例如曹操传等
南极星下载地址:://down.52pk.net/soft/813.htm
主要解决方向是台湾地区制作的游戏的繁体简化
2、按照不同系统的解决方法(主要制作的游戏)
win98系统:玩繁体游戏时可以用南极星解决
2000系统:在2000的控制面板的区域选项里面有系统的语言设置
把中文繁体钩上(要用到2000安装源文件或者2000安装盘
XP系统:下载个ie繁体字库,请去这里下载 ://61.136.152.55/sanguogame/download/tools/winbig5.rar
安装了之后就好了。
3、xp下的乱码解决方法(呕血推荐)
各位XP的用户是不是在玩游戏是无论你用什么转换器都无法解决乱码问题呢?现在我推荐一个肯定好用的XP的乱码转换器,Microsoft Applocale,这个转换器是由微软专门为XP用户发行的,绝对没问题!下载地址==>://patch.ali213.net/view.asp?id=3139
使用方法:先安装,然后点开始菜单,在所有程序上找到Microsoft Applocale,再找到Applocale,点进去,然后下一步,选启动应用程序,再点浏览,选择你要进行转换的乱码游戏的EXE运行文件,然后点下一步,在应用程序的语言上选中文(繁体),然后点下一步,最后你可以选择创建快捷方式,那你下次进入是就不用慢慢再做一次了,最后按完成!那你进入游戏后就会发现乱码问题都解决了!!哈哈!!很爽吧!!如果你下次要再进入,就直接从开始菜单那里进入就可以了!!
参考://bbs.52pk.net/52pk_48_1_35359.html
回答者:fallenlees - 高级魔法师 六级 3-10 18:43
-
繁体版的原因,你可以在你的电脑上安装Microsoft AppLocale,然后更改系统内码,也可以借助第三方的内码转换工具,金山游侠就提供,也可以用magicwin或者南极星
-
最简单的方法,不用下载任何软件!
在控制面板里变更区域设置为中文台湾
缺点是需要重新启动!
另一个解决之道是下载繁简游戏中文通!应该是2.13版!效果很好!
版本说明
在使用简体中文版win2000/xp玩繁体中文或日文游戏,
更改系统区域后要重起才能生效。
本程序免除这个麻烦。
系统要求:
win2000或xp
安装中文台湾(繁体)/日文区域支持
(即在IE里能浏览台湾/香港繁体/日文网页)。
用途:
不用在控制面板里变更区域设置为中文台湾/日语。
使用方法:
"浏览" 选取游戏执行文件,
"命令参数" 游戏执行的命令行参数,如大宇的明星志愿2,需要/m参数。
"字体" 选择繁体中文/日文字体。
繁体中文(big5内码),字体选择PMingLiu,内码选择chinese_big5
日文(shift_JIS内码),字体选择Ms Mincho,内码选择"日文"
"运行" 开始玩,游戏画面出来后本程序即可以退出。
回答者:toyuanye - 经理 四级 2-10 01:05
-
装个翻译软件,南极星和四通利方都可以
回答者:TOTO128 - 试用期 一级 2-10 00:11
文件的“编码”是指什么?
汉字出现乱码有好几种情况,大致可分成四类:网页、文本、文档和文件乱码。第一类是由于港台的繁体中文大五码(BIG5)与大陆简体中文(GB2312)不通用造成的;第二类是Win9X/Win2K系统(菜单、桌面、提示框)显示乱码,这是Win9X/Win2K注册表中有关字体的部分设置不当引起的;第三类是各种应用程序(包括游戏)本来显示中文的地方出现乱码,形成原因比较复杂,有第二类的乱码原因,也可能是软件用到的中文动态链接库被英文动态链接库覆盖造成的;最后一类是邮件乱码。
由于楼主你没有说清楚具体是什么,所以只好写长一些了,呵呵,希望楼主有耐心看完:
(一)、网页、文本和文档文件乱码的消除
网页乱码是浏览器(如IE等)对HTML网页解释时形成的。如果在网页的代码中有形如:〈HTML〉〈HEAD〉〈META CONTENT=“text/html;charset=ISO-8859-1”〉〈/HEAD〉……〈/HTML〉的语句,浏览器在显示此页时,就会出现乱码。因为浏览器会将此页语种辨认为“欧洲语系”。解决的办法是将语种“ISO-8859-1”改为GB2312,如果是繁体网页则改为BIG5。
另一种解决办法是不修改网页代码,事先为浏览器安装多语言支持包(例如在安装IE时要安装多语言支持包),这样在浏览网页出现乱码时,就可以在浏览器中选择菜单栏下的“查看”/“编码”/“自动选择”/简体中文(GB2312),如为繁体中文则选择“查看”/“编码”/“自动选择”/繁体中文(BIG5),其它语言依此类推选择相应的语系,这样可消除网页乱码现象。
还有一种解决办法是利用多内码显示平台来转换内码。常用多内码显示平台有:“南极星”、“四通利方”、“MagicWin 98等等。
网页无乱码保存的方法是:用浏览器打开网页时,在“查看”/“编码”中选择“自动选择”,存盘时保存类型选“web页”,编码选择“UNICOD”,这样保存过的网页再次打开时,在浏览器菜单“查看”、“编码”中不管选择简体中文(GB2312)、简体中文(HZ)还是UNICODE(UTF-8)或繁体中文(BIG5),最终显示都不会出现乱码。
文本、文档文件乱码,一般是繁体中文显示在简体中文系统下或者相反情况造成的。只要把原本是繁体的内码转换为简体内码(或者相反),就可消除乱码。
Word能胜任这类工作,例如要把繁体中文转换为简体中文,方法是:选择要转换内码的文件,在弹出的对话框中,选择“其它编码”中的“繁体中文(BIG5)”一项,打开此文件时就不会出现乱码。无乱码保存方法:在保存时选择“文件”中的“另存为”,先存为“Word文档,存盘后打开再存为纯文本等其它格式;您也可以用Word的“中文简繁转换”工具实现无乱码保存,方法是在菜单栏中选择“工具/语言/中文简繁转换”,内码转换后再保存。
除此之外,消除这类乱码还可用内码转换工具,对BIG5(繁体中文)和GB2312(国标码、简体中文)进行相互转换来实现。常用的内码转换工具有:“飓风简繁通、“内码转换大师、“华语通、“两岸通汉字内码转换器等等
(二)、Win9X/Win2K系统乱码的消除
这类乱码是由于注册表中关于字体部分配置不正常造成的,即使您用内码翻译软件如四通利方、南极星、Magic Win98、两岸通等处理也不会消除。解决办法是:恢复注册表中关于字体部分设置。
如有一台Win9X/Win2K版本相同且显示正常的机器,则可依下列步骤进行恢复:
1.在正常机器上选择“开始”/“运行”,在对话框中键入“REGEDIT”,打开注册表编辑器;
2.光标定位到“HKEY_LOCAL_MACHINE\ SYSTEM\CURRENT CONTROL SET\CONTROL\ FONTASSOC”,选择“注册表/导出注册表文件”,再选择“分支”,导出该分支注册表信息到文件(如LI.REG)中;
3.把LI.REG文件Copy到显示乱码的机器上,在显示乱码机器上运行REGEDIT,选择“注册注册表”/“导入注册注册表”,把LI.REG文件导入注册表中。
如没有Win9X/Win2K版本相同且显示正常的机器,则需要您手工恢复字体部分注册表项,按以下步骤:
1.在乱码机器上打开“开始”——“运行”——REGEDIT,然后回车,打开注册表编辑器;
2.找到“HKEY_LOCAL_MACHINE\SYSTEM\ CURRENT CONTROL SET\CONTROL\FONTASSOC”,正常情况下,会有ASSOCIATED DEFAULTFONTS、ASSOCIATED CHARSET两个文件夹,其正确的内容为:
子目录内容
中文Win98
中文Win98(OEM版)
中文Win2K
AASOCIATED CHARSET
ANSI(00)=“yes”
GB2312(86)=“yes”
DEN(FF)=“yes”
SYMBOL(02)=“no”
ANSI(00)=“yes”
GB2312(86)=“yes”
OEM(FF)=“yes”
SYMBOL(02)=“no”
ANSI(00)=“yes”
OEM(FF)=“yes”
SYMBOL(02)=“no”
ASSOCIATED DEFAULT
FONTS
AssocSystemFont=“simsun.ttf”
FontPackageDecorative=“宋体”
FontPackageDontcare=“宋体”
FontPackageModern=“宋体”
FontPackageRoman=“宋体”
FontPackageScript=“宋体”
FontPackageSwiss=“宋体”
同左栏
AssocSystemFont=“simsun.ttf”
FontPackage=“新宋体”
FontPackageDecorative=“新宋体”
FontPackageDontcare=“新宋体”
FontPackageModern=“新宋体”
FontPackageRoman=“新宋体”
FontPackageScript=“新宋体”
FontPackageSwiss=“新宋体”
3.当出现汉字乱码时,上述两个文件夹中内容就会不完整,有的没有ASSOCIATED CHARSET文件夹或其中内容残缺不全;有的ASSOCIATED DEFAULTFONTS下内容残缺。只要用REGEDIT在“HKEY_LOCAL_MACHINE\SYSTEM\CURRENTCONTROLSET\ CONTROL\FONTASSOC”下,根据以上正确内容恢复即可。
(三)、应用程序(包括游戏)乱码的消除
中文软件菜单等显示界面上出现乱码,可能是由于Windows注册表中关于字体设置的信息不正确地改变而造成的,这时候可以用上述第2点介绍的办法去解决。
如果用上法解决不了,那就是因为软件的中文链接库被英文链接库覆盖而引起的,这种现象经常发生在用微软开发工具例如VB、VC开发的中文软件上,这类软件中,菜单等显示界面上的汉字都是受一个动态链接库(DLL文件)控制,而软件的这个动态链接库一般安装在Windows的System目录下,如果以后安装了某个英文软件也使用同名的动态链接库,则英文软件的动态链接库就会覆盖WINDOWS\SYSTEM下的中文软件的动态链接库,这样,运行中文软件时就会调用英文的动态链接库,因此出现乱码。解决办法是重新安装中文软件,恢复中文动态链接库即可。
(四)、邮件乱码的消除
1.邮件乱码原因及其排除
邮件乱码的形成原因很多,主要有以下几个方面:
(1)邮件服务器不支持8位(非ASCII码格式)
传输邮件传输机制或邮件编码的不同,可能造成邮件服务器不支持8位(非ASCII码格式)传输而形成邮件乱码。例如直接发送中文或二进制等非ASCII码格式的邮件(如中文双字节文件、文件.jpg、可执行文件.exe或压缩文件.zip等二进制文件)时,邮件服务器有可能无法处理,便把信件中每个字符的第8位都过滤掉,从而造成邮件信息的失真或损坏,在收到邮件时就是一堆乱码。
对策:在发送8位格式的文本文件时,必须事先进行编码,将文件转换为7位ASCII码或更少位数的格式,然后才能保证文件的正确传送。收件人收到7位或更少位格式的邮件后,可以再转换为8位的格式,这样就可避免乱码。
(2)收发端使用的E-mail软件和设置不同
一般E-mail软件的“附件”功能都可以自动对信件先进行编码,然后送出。这样只要收信人使用的E-mail软件(如Outlook、Netscape E-mail等)能区别信件的编码方式,就可以自动将信件解码。然而由于收发件人所用的E-mail软件默认配置不同或收发件人自己定制的一些选项不同,所以在收到编码的信件后,系统不一定能识别出信件所用的编码方法,自然无法自动解码,这样就会出现乱码。
对策:可以用Winzip+IE来解码,方法是:把乱码邮件的内容,拷贝到剪贴板中,然后将其粘贴到记事本中,存为文本文件(例如LI.txt),再将其后缀改为.uue(改为LI.uue),点击此文件,会启动Winzip,然后启动IE,把Winzip中的001.txt文件拖到IE窗口中,就会显示邮件原来的内容,而不会看到乱码。
也可以根据邮件中的关键字符判断编码方法,选取合适的解码软件进行解码。
邮件的编码方式主要有:UUENCODE、Base64 encode、QP-encode、BINHEX等。
UUENCODE:这是UNIX环境下使用的编码方式,目前已经很少用,大体格式为:
begin 644 kk.zip M1G)O;2!I;&EN+F)B3T!C(VEE+FYC='4N961U+G1W(%=E9"!.;W8@(#8@,3(ZM,SDZ,C4@,3DY-@I296-E:79E9#H@9G)O;2!F;&%B;6%I;"YF;&%B+F9U:FET……
end
特征:乱码前面含有“begin xxx”,后面是编码前的原始文件名(如kk.zip),接着是已经过编码的信件内容(如上述的乱码部分)最后一行为“end”。
解码办法:可用BECKY!EUDORA等E-mail软件,选择编码中相应的选项就可解码,也可以在E-mail软件中保存乱码邮件,存为后缀为“.UUE”格式的文件,然后用Winzip解码展开。解码后就会消除乱码。
MIME/BASE64 encode:该编码方式将3个字节(8位)用4个字节(6位)表示,由于编码后的内容是6位的,因此可避免第8位被截掉,大体格式为:
MIME-Version:1.0
Content-Type:text/plain; charset="us-ascii"
Content-Transfer-Encoding:base64
Status:R
SGmhQbF6pm6hSafapmK69Lj0pFexb6q+sXqsT6Skp OWrSKXzsN3DRLFNrmGhQQ0Kq1+sTqq6vdCx<BR>0LF6tFit07Ddw0ShRw0KD QqtuqX9p2m2RLF6p9qoz6XOIE 1Py3Jvc29mdCuiBJbnRlcm5ldCBN……
特征:乱码前一般有如下几部分“信头”:Content-Type(内容类型)、charset(字符集)和Content-Transfer-Encoding(内容传输乱码方式)。
解码办法:用E-mail软件,选择编码中Base64 选项就可解码,解码后会消除乱码。
QpencodeQP:全称“Quoted-Printable Content-Transfer-Encoding”。因为这种格式邮件的内容都是ASCII字符集中可以打印的字符,所以名称中含有Printable。大体格式为:
=A1A=B1z=A6n=A1I=A7=DA=A6b=BA=F4=B8=F4=A4W
=B1o......
=E5==ABH=A5=F3=B0=DD=C3D=B1M=Aea=A1A......
特征:内容通常有很多等号“=”,因此不需要看“信头”也可以判断是否为QP编码。
解码办法:把邮件中类似A1A=B1z=A6n...的部分编码全部复制下来,贴到一个新的纯文本文件中,然后在文件头部加入Quoted-Pintable格式的文件头:
Contenet-Type:text/plain;Charset="GB2312"
Content-Transfer-Encoding;Quoted-Pintable
然后以“EML”为后缀保存文件,用管理器双击打开文件即可显示正确的内容。如果还有部分汉字乱码,可以用Winzip对存盘后的EML文件进行解压,即可看到正确的内容。
BINHEX:这种编码方式大体格式为:
(This file must be converted with Binhex4.0)
SGmhQbF6pm6hSafapmK69Lj0pFexb6qssTqq6vdCx<BR> 0LF6tFit07Ddw0ShRw0KDQqtuqX9p2m2RLF6p9q
oz6XOIE……
解码办法:用E-mail软件对它解码;也可在E-mail软件中保存乱码邮件,存为后缀为“.HQX”格式的文件,然后用Winzip解码展开。
解码后会消除乱码。
UTIF-7/UTIF-8:它们是UNICODE的两种转换码。
UTIF-7编码方式大体格式为:
+SGmhQbF/6pm6hSafapmK69L/j0pFexb6q+sXqsT6Skp. OWrSKXzsN3DRLFNrmGhQQ0Kq1-sTqq6vdCx<BR>0LF6tFit07Ddw0ShRw0KD QqtuqX9p2m2RLF6p9qoz6XOIE 1Py3Jvc29mdCuiBJbnRlcm5ldCBN……
解码办法:在原E-mail头加入以下信息:
MIME-Version:1.0
Content-Type:text/plain; charset="utf-7"
Content-Transfer-Encoding:7bit
插入后与字符留一空行,将邮件存为“EML”后缀,然后用Outlook即可解码,消除乱码。
UTIF-8
解码办法:在原E-mail头加入以下信息:
MIME-Version:1.0
Content-Type:text/plain; charset="utf-8"
Content-Transfer-Encoding:8bit
将邮件存为“EML”后缀,然后用Outlook即可解码,消除乱码。
(3)操作系统语种不同
对于中文电子邮件,如果收信方所用的操作系统是英文环境而且没有中文系统或未切换为中文(如四通利方或南极星等)编码方式,也会无法看到中文只见乱码。所有的双字节字符(如中文简/繁体的GB和BIG5码及日文的JIS、EUC和朝鲜文的 KSC码等)在非本语种操作系统下都会出现乱码。同样在中文简体的GB码环境下看其它双字节字符时也只能看到乱码。
对策:安装多语言支持包或使用多内码显示平台(如四通利方或南极星等),对收到的邮件,根据其使用的语种切换到相应的编码方式即可消除乱码。
2.为了避免别人收到乱码,发信方应注意:
(1) E-mail软件中的正确设置
使用英文E-mail软件应设置成:
文字设定Default CHARSET:ISO 8859-1
(Latin1)
编码方式Encoding:Quoted-Printable,不可选择7位(因为7位不支持中文)
字码页Code Page(可选):936或HZ-GB-2312,
以支持整字识别邮件格式:MIME
字体:宋体
中文E-mail软件应设置成:
文字设定Default CHARSET:简体中文GB2312
编码方式Encoding:Quoted-Printable邮件格式:MIME
字体:宋体
Outlook Express中应把“简体中文(GB2312)作为默认的邮件使用语言,选择“国际设置”/为接收的所有邮件使用默认的编码。
(2)发送前将邮件按7位格式重新编码
在发送8位格式的文本文件时,必须事先进行编码,将文件转换为7位ASCII码或更少位数的格式,然后才能保证文件的正确传送。收件人收到7位或更少位格式的邮件之后,可以再转换为8位的格式,这样就可以阅读了。
在邮件客户端软件中的书写(撰写)选项中,设定默认自动为7位编码。
(3)转换成合适的内码
在E-mail软件的书写(撰写)选项中,设定默认自动为7位编码。对用汉字系统编辑的中文邮件在发送前,最好在固定的签字栏中注明自己所使用的汉字码标准(如:GB2312、中文HZ、GBK);港澳台及东南亚地区邮件作者在使用BIG5码撰写完邮件、向内地发送前要转换成上述三种简体国标码中的一种形式并在签字栏中注明。如不转换则可能无法阅读,因为国内用户使用的邮件系统有很多不支持BIG5码。
(4)发送重要信息时先发测试信
发送重要信息时,为了确认是否无须编码即可发送正文,应该先发送测试信。而且还应确定收件人能否对附件文件进行解码。如果发送已经编码的邮件,则最好添加足够的“信头”信息,以便收件人知道所需的解码方法。建议对UUENCODE/UUDeview编码方式用UUENCODING作信头,对Mpack编码方式用Base64 encoding作信头。
(5)尽量利用“附件”功能发送文件
几乎所有的邮件软件,如Netscape、The Bat!、 Becky! 等邮件系统附加这类非标准 ASCII码格式的文件时,附加文件通常可以自动进行“Base64”方式编码(仅对附件部分进行编码)。在用“附件”方式发送邮件之前,无需进行编码;否则适得其反。因为邮件软件能够自动成功解码这类“附加”文件,因此在发送中文类邮件时应该首选这种方法。
如果无法以附件方式发送文件,则必须在正文中发送中文或二进制文件如果发/收件人之间远隔万里,则传送过程中,第八位将可能被截掉。这时最好先在正文中用中文给收件人发一封测试信,并了解对方能否正确收到邮件正文。如果第八位被截掉,则收件人将会看到一些乱码,而不是上述的uu/b64/Qp等格式,而且这种信件几乎不可恢复。
对策:在Netscape、Eudora或Pegasus Mail等你所使用的邮件系统中,选择其首选项或选项配置中的“Quoted Printalbe”或“MIME encoding”。
(6)选择优秀的客户端邮件软件
选择优秀E-mail收发软件可有效解决邮件乱码。
3.为排除乱码,收信方应注意:
查找邮件:签字栏或正文中有无指明本邮件所使用汉字标准码类别的英文字符;在“查看(V)”下拉菜单中选中“语言”,随后出现的菜单中会包括本系统所能支持的全部汉字标准,在其中单击邮件中所指明的一种。如果收到的邮件中没有指明其所使用的汉字标准,则只可按顺序单击,直到邮件正文显示正确为止(数个汉字标准中必有一个前面有“.”标记,此即您编辑器所用的汉字标准)。若使用的是Netscape,可在Option菜单的Document Encode中选择相应的项目。
4.在非中文平台上中文邮件不出现乱码方法
当对方没有中文平台而打开您发的中文邮件时,就会出现乱码。解决办法有两种:
(1)用E-mail AID之类的工具
UCWIN GOLD 1.0附带的工具E-mail AID可把文本文件转换为AID格式文件,大小只比原TXT文件增加几K。写好中文邮件后,用文本格式存盘,然后用E-mail AID以AID格式保存,最后把此文件连同E-mail AID一起作为附件插在信中。对方收到信后,只需运行E-mail AID打开AID格式文件即可看到汉字,不管对方在何语言平台下,都不会出现乱码。
(2)把中文邮件以图形格式保存
用画笔等绘图软件书写中文邮件,在中输入文字,用默认的BMP格式保存,将属性置为黑白模式(以减少BMP体积),然后用Winzip把它压缩成ZIP格式,作为附件在邮件中发送,这样不管对方在何语言平台下,都不会出现乱码。这种方法的缺点是生成的BMP中文邮件体积太大。
小弟玩三国志7中文版+威力加强版 求内码转换工具!要下载地址!谢!
编码指的就是字符集合,
编码是根据一定的协议或格式把模拟信息转换成比特流的过程。
在计算机硬件中,编码(coding)是在一个主题或单元上为数据存储,管理和分析的目的而转换信息为编码值(典型地如数字)的过程。在软件中,编码意味着逻辑地使用一个特定的语言如C或C++来执行一个程序。在密码学中,编码是指在编码或密码中写的行为。
将数据转换为代码或编码字符,并能译为原数据形式。是计算机书写指令的过程,程序设计中的一部分。在地图自动制图中,按一定规则用数字与字母表示地图内容的过程,通过编码,使计算机能识别地图的各地理要素。
n位二进制数可以组合成2n个不同的信息,给每个信息规定一个具体码组,这种过程也叫编码。
数字系统中常用的编码有两类,一类是二进制编码,另一类是二—十进制编码。
汉字的编码体系
1.ASCII与Binary
我们日常接触到的文件分ASCII和Binary两种。ASCII是“美国信息交换标准编码”的英文字头缩写,可称之为“美标”。美标规定了用从0到127的128个数字来代表信息的规范编码,其中包括33个控制码,一个空格码,和94个形象码。形象码中包括了英文大小写字母,阿拉伯数字,标点符号等。我们平时阅读的英文电脑文本,就是以形象码的方式传递和存储的。美标是国际上大部分大小电脑的通用编码。
然而电脑中的一个字符大都是用一个八位数的二进制数字表示。这样每一字符便可能有256个不同的数值。由于美标只规定了128个编码,剩下的另外128个数码没有规范,各家用法不一。另外美标中的33个控制码,各厂家用法也不尽一致。这样我们在不同电脑间交换文件的时候,就有必要区分两类不同的文件。第一类文件中每一个字都是美标形象码或空格码。这类文件称为“美标文本文件”(ASCII Text Files),或略为“文本文件”,通常可在不同电脑系统间直接交换。第二类文件,也就是含有控制码或非美标码的文件,通常不能在不同电脑系统间直接交换。这类文件有一个通称,叫“二进制文件”(Binary Files)。
2.国标、区位、“准国标”
“国标”是“中华人民共和国国家标准信息交换用汉字编码”的简称。国标表(基本表)把七千余汉字、以及标点符号、外文字母等,排成一个94行、94列的方阵。方阵中每一横行叫一个“区”,每个区有九十四个“位”。一个汉字在方阵中的坐标,称为该字的“区位码”。例如“中”字在方阵中处于第54区第48位,它的区位码就是5448。
其实94这个数字。它是美标中形象码的总数。国标表沿用这个数字,本意大概是要用两个美标形象符代表一个汉字。由于美标形象符的编码是从33到126,汉字区、位码如果各加上32,就会与美标形象码的范围重合。如上例“中”字区、位码加上32后,得86,80。这两个数字的十六进制放在一起得5650,称为该字的“国标码”,而与其相对应的两个美标符号,VP,也就是“中”字的“国标符”了。
这样就产生了一个如何区分国标符与美标符的问题。在一个中英文混用的文件里,“VP”到底代表“中”字呢,还是代表某个英文字头缩写?电子工业部第六研究所开发CCDOS的时候,使用了一个简便的解决方案:把国标码的两个数字各加上128,上升到非美标码的位置。(改变后的国标码,习惯上仍叫“国标”。)
这个方案固然解决了原来的问题,可是新的问题随之产生。中文文件成了“二进制文件”,既不能可靠地在不同电脑系统间交换,也不与市场上大部分以美标符号为设计对象的软件兼容。
为了区分以上两种“国标”,我们把原与美标形象码重合的国标码称为“纯国标” ,而把CCDOS加上128的国标码称为“准国标”。
3.GBK码:
GBK码是GB码的扩展字符编码,对多达2万多的简繁汉字进行了编码,简体版的Win95和Win98都是使用GBK作系统内码。
从实际运用来看,微软自win95简体中文版开始,系统就用GBK代码,它包括了TrueType宋体、黑体两种GBK字库(北京中易电子公司提供),可以用于显示和打印,并提供了四种GBK汉字的输入法。此外,浏览器IE4.0简体、繁体中文版内部提供了一个GBK-BIG5代码双向转换功能。此外,微软公司为IE提供的语言包中,简体中文支持(Simplified Chinese Language Support Kit)的两种字库宋体、黑体,也是GBK汉字(珠海四通电脑排版系统开发公司提供)。其他一些中文字库生产厂商,也开始提供TrueType或PostScript GBK字库。
许多式的中文平台,如南极星、四通利方(Richwin)等,提供GBK码的支持,包括字库、输入法和GBK与其他中文代码的转化器。
互联网方面,许多网站网页使用GBK代码。
但是多数搜索引擎都不能很好的支持GBK汉字搜索,大陆地区的搜索引擎有些能不完善的支持GBK汉字检索。
其实,GBK是又一个汉字编码标准,全称《汉字内码扩展规范》(Chinese Internatial Code Specification),1995年颁布。GB是国标,K是汉字“扩展”的汉语拼音第一个字母。
GBK向下与GB-2312编码兼容,向上支持ISO 10646.1国际标准,是前者向后者过渡的一个承启标准。
GBK规范收录了ISO 10646.1中的全部CJK汉字和符号,并有所补充。具体包括:GB 2312中的全部汉字、非汉字符号;GB 13000.1中的其他CJK汉字。以上合计20902个GB化汉字;《简化总表中》未收入GB 13000.1的52个汉字;《康熙字典》以及《辞海》中未被收入GB 13000.1的28个部首及重要构件;13个汉字结构符;BIG-5中未被GB 2312收入、但存在于GB 13000.1的139个图形符号;GB 12345增补的6个拼音符号;GB 12345增补的19个竖排图形符号(GB 12345较GB 2312增补竖排标点符号29个,其中10个未被GB 13000.1收入,故GBK亦不收);从GB 13000.1的CJK兼容区挑选出的21个汉字;GB 13000.1收入的31个IBM OS/2专用符号。GBK亦用双字节表示,总体编码范围为0x8140~0xFEFE之间,首字节在0x81~0xFE之间,尾字节在0x40~0xFE之间,剔除0x××7F一条线,总计23940个码位,共收入21886个汉字和图形符号,其中汉字(包括部首和构件)21003个,图形符号883个。
4.BIG5码:
BIG5码是针对繁体汉字的汉字编码,目前在台湾、香港的电脑系统中得到普遍应用。BIG5码的编码范围参考下文。
5.HZ码:
HZ码是在Internet上广泛使用的一种汉字编码。“HZ”方案的特点,是以“纯国标”的中文与美标码混用。那么“HZ”是怎样区分国标符和美标符的呢?答案其实也很简单:当一串美标码中间插入一段国标码的时候,我们便在国标码的前面加上~,后面加上~。这些附加码分别叫“逃出码”和“逃入码”。 由于这些附加码本身也是美标形象码,整个文件就俨然是一个美标文本文件,可以安然地 在电脑网上传递,也和大部分英文文本处理软件兼容。
6.ISO-2022CJK码:
ISO-2022是国际标准组织(ISO)为各种语言字符制定的编码标准。用二个字节编码,其中汉语编码称ISO-2022 CN,日语、韩语的编码分别称JP、KR。一般将三者合称CJK码。目前CJK码主要在Internet网络中使用。
7.UCS 和 ISO 10646:
1993年,国际标准ISO10646 定义了通用字符集 (Universal Character Set, UCS)。 UCS 是所有其他字符集标准的一个超集。它保证与其他字符集是双向兼容的。就是说, 如果你将任何文本字符串翻译到 UCS格式,然后再翻译回原编码, 你不会丢失任何信息。
UCS 包含了用于表达所有已知语言的字符。不仅包括拉丁语,希腊语,斯拉夫语,希伯来语,阿拉伯语,亚美尼亚语和乔治亚语的描述, 还包括中文,日文和韩文这样的象形文字,以及平名,片名,孟加拉语, 旁遮普语果鲁穆奇字符(Gurmukhi), 泰米尔语, 印.埃纳德语(Kannada),Malayalam,泰国语, 老挝语, 汉语拼音(Bopomofo), Hangul,Devangari,Gujarati, Oriya,Telugu 以及其它语种。对于还没有加入的语言, 由于正在研究怎样在计算机中最好地编码它们, 因而最终它们都将被加入。这些语言包括Tibetian,高棉语,Runic(古代北欧文字),埃塞俄比亚语, 其他象形文字,以及各种各样的印-欧语系的语言,还包括挑选出来的艺术语言比如 Tengwar,Cirth 和 克林贡语(Klingon)。UCS 还包括大量的图形的,印刷用的,数学用的和科学用的符号,包括所有由 TeX,Postscript, MS-DOS,MS-Windows, Macintosh, OCR 字体, 以及许多其他字处理和出版系统提供的字符。
ISO 10646 定义了一个 31 位的字符集。 然而, 在这巨大的编码空间中, 迄今为止只分配了前 65534 个码位 (0x0000 到 0xFFFD)。这个UCS的16位子集称为基本多语言面 (Basic Multilingual Plane, BMP)。 将被编码在16位BMP以外的字符都属于非常特殊的字符(比如象形文字), 且只有专家在历史和科学领域里才会用到它们。按当前的, 将来也许再也不会有字符被分配到从0x000000到0x10FFFF这个覆盖了超过100万个潜在的未来字符的 21 位的编码空间以外去了。ISO 10646-1标准第一次发表于1993年, 定义了字符集与 BMP 中内容的架构。定义 BMP以外的字符编码的第二部分 ISO 10646-2 正在准备中, 但也许要过好几年才能完成。新的字符仍源源不断地加入到 BMP 中, 但已经存在的字符是稳定的且不会再改变了。
UCS 不仅给每个字符分配一个代码, 而且赋予了一个正式的名字。表示一个 UCS 或 Unicode 值的十六进制数, 通常在前面加上 “U+”, 就象U+0041 代表字符“拉丁大写字母A”。UCS字符U+0000到U+007F 与 US-ASCII(ISO 646) 是一致的, U+0000 到 U+00FF 与 ISO 8859-1(Latin-1) 也是一致的。从 U+E000 到 U+F8FF,已经BMP 以外的大范围的编码是为私用保留的。
1993年,ISO10646中定义的USC-4 (Universal Character Set) ,使用了4 个字节的宽度以容纳足够多的相当可观的空间,但是这个过于肥胖的字符标准在当时乃至现在都有其不现实的一面,就是会过分侵占存储空间并影响信息传输的效率。 与此同时,Unicode 组织于约 10 年前以 Universal, Unique和Uniform 为主旨也开始开发一个16位字符标准, 为避免两种16位编码的竞争,1992年两家组织开始协商,以期折衷寻找共同点,这就是今天的 UCS-2 (BMP,Basic Multilingual Plane,16bit) 和Unicode,但它们仍然是不同的方案。
8.Unicode码:
关于Unicode我们需要追溯一下它产生的源源。
当计算机普及到东亚时,遇到了使用表意字符而非字母语言的中、日、韩等国家。在这些国家使用的语言中常用字符多达几千个,而原来字符用的是单字节编码,一张代码页中最多容纳的字符只有28=256个,对于使用表意字符的语言是在无能为力。既然一个字节不够,自然人们就用两个字节,所有出现了使用双字节编码的字符集(DBCS)。不过双字节字符集中虽然表意字符使用了两个字节编码,但其中的ASCII码和日文片名等仍用单字节表示,如此一来给程序员带来了不小的麻烦,因为每当设计到DBCS字符串的处理时,总是要判断当中的一个字节到底表示的是一个字符还是半个字符,如果是半个字符,那是前一半还是后一半?由此可见DBCS并不是一种非常好的解决方案。
人们在不断寻找这更好的字符编码方案,最后的结果就是Unicode诞生了。Unicode其实就是宽字节字符集,它对每个字符都固定使用两个字节即16位表示,于是当处理字符时,不必担心只处理半个字符。
目前,Unicode在网络、Windows系统和很多大型软件中得到应用。
关于GB编码的一些常识
GB编码标准中,比较常用的是GB2312和GBK两种,GB2312是GBK的一个子集,GB2312编码范围是 0xA1A1 - 0xFEFE ,如果纯粹的 GB2312编码,处理起来是什分简单的,但处理GBK字符集时有些小的提示,先说说GBK编码的标准吧:
GBK 用双字节表示,总体编码范围为 8140-FEFE,首字节在 81-FE 之间,尾字节在 40-FE 之间,剔除 xx7F 一条线。总计 23940 个码位,共收入 21886 个汉字和图形符号,其中汉字(包括部首和构件)21003 个,图形符号 883 个。
全部编码分为三大部分:
1. 汉字区。包括:
a. GB 2312 汉字区。即 GBK/2: B0A1-F7FE。收录 GB 2312 汉字 6763 个,按原顺序排列。
b. GB 13000.1 扩充汉字区。包括:
(1) GBK/3: 8140-A0FE。收录 GB 13000.1 中的 CJK 汉字 6080 个。
(2) GBK/4: AA40-FEA0。收录 CJK 汉字和增补的汉字 8160 个。
CJK 汉字在前,按 UCS 代码大小排列;增补的汉字(包括部首和构件)在后,按《康熙字典》的页码/字位排列。
2. 图形符号区。包括:
a. GB 2312 非汉字符号区。即 GBK/1: A1A1-A9FE。其中除 GB 2312 的符号外,
还有 10 个小写罗马数字和 GB 12345 增补的符号。计符号 717 个。
b. GB 13000.1 扩充非汉字区。即 GBK/5: A840-A9A0。BIG-5 非汉字符号、结构符和“○”排列在此区。计符号 166 个。
3. 用户自定义区:分为(1)(2)(3)三个小区。
(1) AAA1-AFFE,码位 564 个。
(2) F8A1-FEFE,码位 658 个。
(3) A140-A7A0,码位 672 个。
第(3)区尽管对用户开放,但限制使用,因为不排除未来在此区域增补新字符的可能性。
这里有几个小技巧:
一、在php中,字符编码是按所发送的编码为准的,因些使用的就是用户输入的编码,不会自动改变,但在asp中,默认的编码是unicode,这样我们很容易就能得到gbk->unicode的编码对照表,这样即使在毫无基础库的情况下也能很容易的实现gbk到utf-8的转换了;
二、由于GBK是高位最低数值是0x40,即是64,因此,有时候组织一些涉及中文的字串时,分割字符最好用64之前的ascii码,这样在任意情况下替换或分割都不会出现乱码,比较常用的是 ","、";"、":"、" "、" "、" ",这些字符永远都不会给gb编码添乱。
幻想水浒传2内码问题
MICWIN 98(最佳老游戏转码工具)
://.egame365/pcgames/patchdown/yxgj/2006-01-06/16546.html
中文之星2001完美破解简装版(WIN98下最佳简繁体内码转换软件)
://.egame365/pcgames/patchdown/yxgj/2006-01-06/16544.html
Microsoft Applocale(微软出品的WINXP下最佳转内码工具)
://.egame365/pcgames/patchdown/yxgj/2006-01-06/16543.html
化繁为简 V2.13版(最佳游戏简繁体转换软件)
://.egame365/pcgames/patchdown/yxgj/2006-01-06/16542.html
更改游戏内码问题
给你说三种可行的解决乱码问题的办法(不可行的很多,改注册表啊,注册什么这个那个啊,我就不说了)
目前主要是台湾地区游戏和光荣系列游戏需要繁体或者乱码需要解决,可以按照常规方法或是不同系统进行分类解决
1、常规软件:内码转化工具MagicWin或者南极星
内码转化工具MagicWin下载地址:://down.52pk.net/soft/730.htm
主要解决方向是光荣系列游戏的乱码问题,例如曹操传等
南极星下载地址:://down.52pk.net/soft/813.htm
主要解决方向是台湾地区制作的游戏的繁体简化
2、按照不同系统的解决方法(主要制作的游戏)
win98系统:玩繁体游戏时可以用南极星解决
2000系统:在2000的控制面板的区域选项里面有系统的语言设置
把中文繁体钩上(要用到2000安装源文件或者2000安装盘
XP系统:下载个ie繁体字库,请去这里下载 ://61.136.152.55/sanguogame/download/tools/winbig5.rar
安装了之后就好了。
3、xp下的乱码解决方法(呕血推荐)
各位XP的用户是不是在玩游戏是无论你用什么转换器都无法解决乱码问题呢?现在我推荐一个肯定好用的XP的乱码转换器,Microsoft Applocale,这个转换器是由微软专门为XP用户发行的,绝对没问题!下载地址==>://patch.ali213.net/view.asp?id=3139
使用方法:先安装,然后点开始菜单,在所有程序上找到Microsoft Applocale,再找到Applocale,点进去,然后下一步,选启动应用程序,再点浏览,选择你要进行转换的乱码游戏的EXE运行文件,然后点下一步,在应用程序的语言上选中文(繁体),然后点下一步,最后你可以选择创建快捷方式,那你下次进入是就不用慢慢再做一次了,最后按完成!那你进入游戏后就会发现乱码问题都解决了!!哈哈!!很爽吧!!如果你下次要再进入,就直接从开始菜单那里进入就可以了!!
参考://bbs.52pk.net/52pk_48_1_35359.html
APPLOCLE 并不好
你试用游戏修改大师
可以在游戏运行的时候追踪内存的变化而加以修改,从而得到无限生命或者无限金钱之类的特殊效果,让您顺利过关。您不妨下载试试,相信您一定会喜欢它的^_^
://.wangmeng.cn/Soft/GOODSOFT/game/200610/6601.html
参考资料:
://.wangmeng.cn/Soft/GOODSOFT/game/200610/6601.html关于乱码问题
请先下载
://ftp.pconline.cn/pub/download/200306/loc.msi
安装完成,运行程序
进入主菜单有2个选项
第1个是设定系统永久性的启动语言内码或删除已经做过的设定,由于会干扰其它程序内码,而使其它程序产生乱码,这条没用
第2个是指定单一程序启动语言内码,点选后,必须在下面选择游戏所在位置数据夹的路径,直到指定游戏目录下patch.exe文件
第三页 请选择中文(繁体)
第四页 完成确认
对于以前所有本论坛介绍的输入方法,都必须将游戏使用窗口模式才能实现,经过我最近的研究唯一能实现全屏无障碍(绝对人家能看懂,并且有选字条)输入的方法如下:
前提,必须使用上面的转码方式。
请先下载微软拼音4.0
://soft.star.cn/down.asp?id=244&no=1
安装完成后,设置微软拼音4.0属性
全屏进游戏然后切换到4.0,一切就ok了。(推荐把输入法里的3.0暂时先删掉,省得进游戏2个微软输入法不好找)
不过微软拼音安装的时候有个最大bug,就是只默认c:\windows为系统目录,如果有谁的系统不在这个目录,就要把C盘SYSTEM下关于输入法的那个文件夹(名字不记得了,好象是3个字母的 )全部复制到你的系统盘相应目录下。
://.pcforest.cn
://.wanbusi/Article/j//200501/15387.html